
Simply Chinese version: Machine learning for beginners
機械学習を学ぶためのロードマップ

機械学習や深層学習は、人工知能の分野で重要な役割を果たしています。機械学習や深層学習は、コンピュータが膨大な量のデータを分析し、そのパターンを見つけることで、自動化、最適化、予測などの問題を解決することができます。
これにより、半導体、ビジネス、医療、金融、自動運転、ロボット工学などの分野で、大幅な効率化や革新がもたらされることが期待されています。
機械学習や深層学習を学ぶことで、以下のようなメリットがあります。
1.自分自身のキャリアアップにつながる可能性があります。特に、データサイエンティストや機械学習エンジニアなどの需要が高まっている現在、スキルアップすることで就職や転職の機会が広がるでしょう。
2.問題解決に役立つ、自分自身のビジネスやプロジェクトにも役立ちます。たとえば、自動化、最適化、予測などの問題を解決するために機械学習や深層学習を応用することができ、生産性や効率性の向上につながることが期待されます。
3.技術の進歩に貢献できます。 機械学習や深層学習の技術を習得することで、新しいアルゴリズムの開発や研究に貢献できます。また、オープンソースの機械学習フレームワークを使ったプロジェクトに参加することで、技術の進歩に貢献することも可能です。
4.社会に貢献することにもつながります。医療分野では、患者の診断や治療に機械学習や深層学習を応用することができ、より早期の診断やより適切な治療法の提供が可能になることが期待されます。また、自動運転技術の発展により、交通事故の減少や運転ストレスの軽減など、社会全体の安全や快適性に貢献することが期待されます。
データサイエンスになるためには、以下の手順を考慮することがおすすめ:
1. 必要なスキル: 統計学、プログラミング、データ処理、データベース、機械学習、データ可視化など。
2. 統計学: データの分析やモデルの構築
3. プログラミング: Python、R、JAVA、C/C++/C#、htmlなど
4. データベース: 大規模なデータセットを効率的に処理するため、SQL、MySQL、Oracleなど
5. 機械学習: CNN、RNNなど
6. データ可視化技術: Tableau、PowerBI、Matplotlib、Angularなど
7. プロジェクトの実践: 実データを用いて分析や予測モデルの構築を行う。
機械学習で初心者から専門家までの学習手順は、以下のステップにまとめられます。
1.基本知識
機械学習を始めるには、いくつかの基本的なスキルを身に付ける必要があります。すべての機械学習は、データから情報を抽出することに関係しています。そのためには、線形代数、微積分、確率論、統計学などの数学的な知識が必要になります。
また、プログラミング経験も必要です。Pythonが深層学習の分野で広く使われているので、Pythonの基礎的な知識を身につけることをおすすめします。
おすすめpythonツール: Miniconda(仮想環境の構築), Anaconda, Jupyter Notebook, PyCharm, Visual Studio Code
2.基礎アルゴリズム
線形回帰, sklearn, 勾配降下法, k-means, L1/L2正則化, 最尤推定, SVM, 順伝播型ニューラルネットワーク, 決定木, PCA(主成分分析), ランダムフォレスト, ベイズの定理, Softmax Regression, 活性化関数(ReLU, sigmoid, tanh, GELU), dropout, weight decay, overfit, underfit, 勾配消失, 勾配爆発 など。
 非線形SVM
非線形SVM 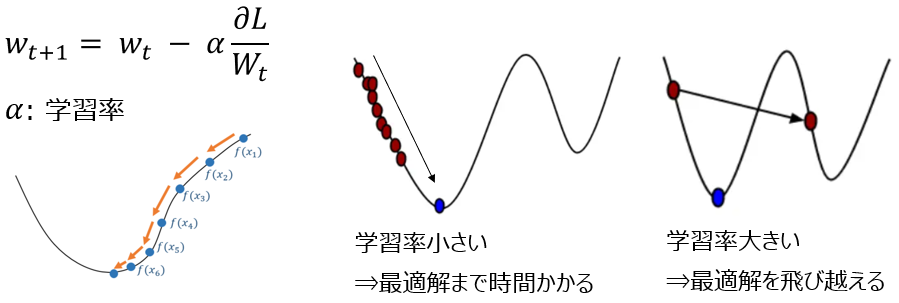 Stochastic Gradient Descent
Stochastic Gradient Descent
3.ネットワーク
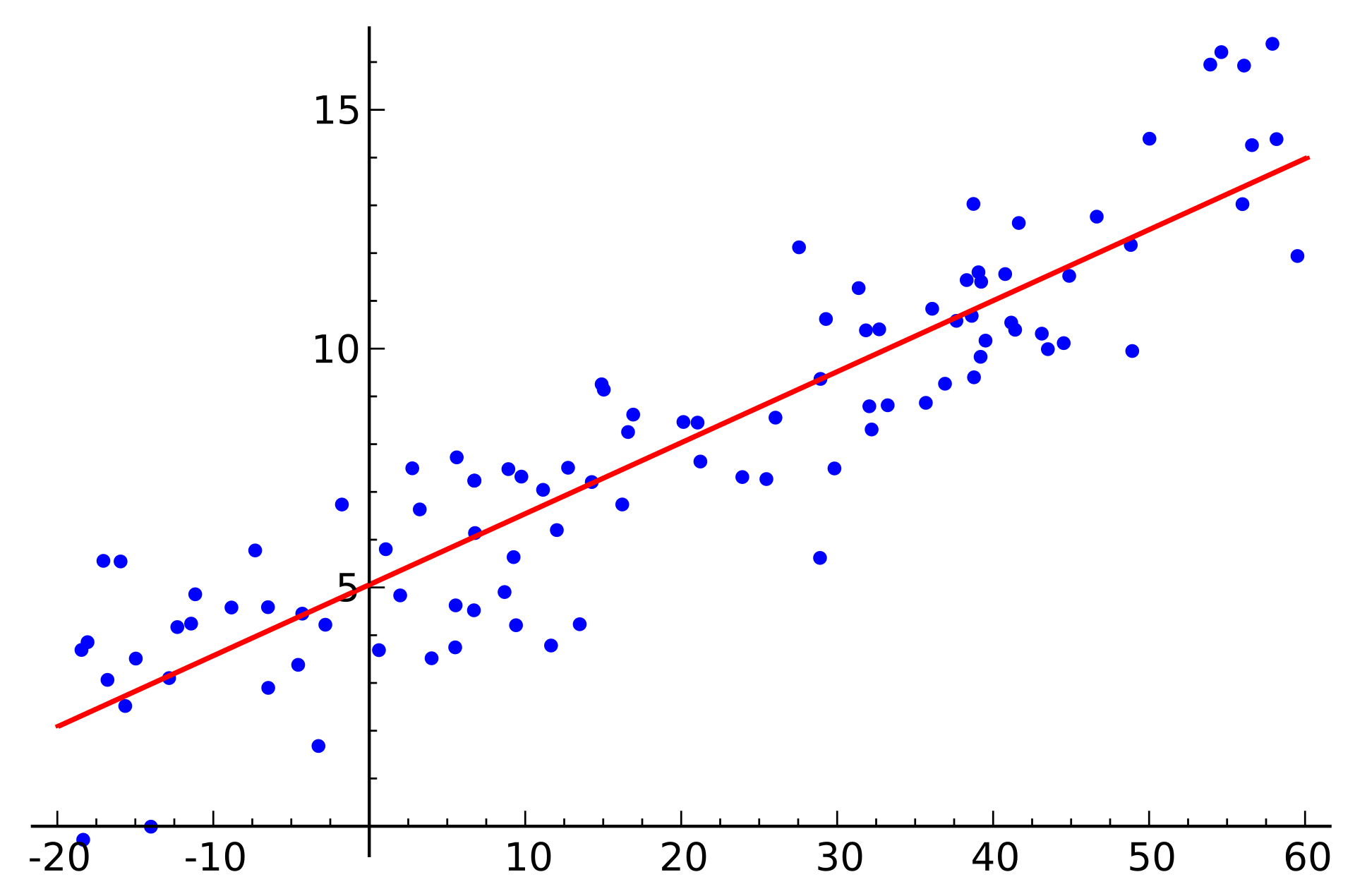
(1) Linear Regression(線形回帰)
wiki: 線形回帰
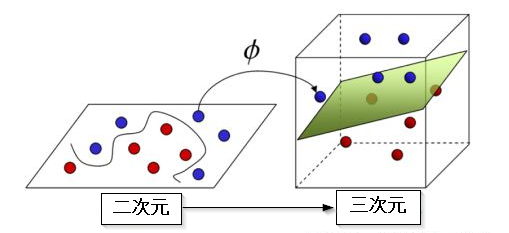
「回帰」とは、モデリングのための手法の一種であり、独立変数と従属変数の関係を分析することで、入力と出力の関係をキャラクタライズすることを目的としています。 例えば、住宅や株の価格の予測、入院患者の滞在期間の予測、小売売上高の需要予測などに使われます。ただし、すべての予測問題が古典的な回帰問題ではありません。 機械学習においては、一連のカテゴリ間のメンバーシップを予測する分類問題がよく用いられます。
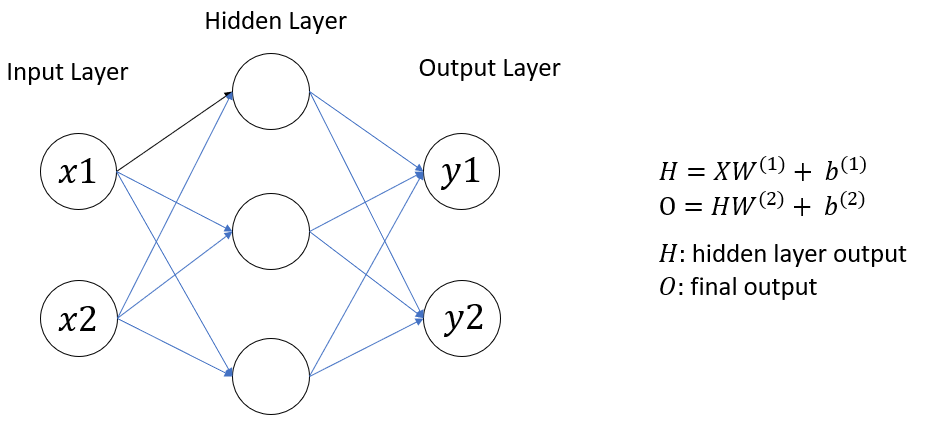
(2) MLP(Multilayer perceptron, 多層パーセプトロン)
wiki: 多層パーセプトロン
最も基本的なディープニューラルネットワークは、多層パーセプトロンと呼ばれます。これは、複数の層から成るニューロンのネットワークで、それぞれの層が下位層(入力を受け取る)と上位層(出力を与える)に完全に接続されています。多層パーセプトロンは、機械学習や人工知能の分野で広く使われており、画像認識、音声認識、自然言語処理などの問題に適用されます。ニューラルネットワークの各層では、入力信号に対して重み付けとバイアスが行われ、その出力が次の層に入力されることで、より高度な特徴の抽出や分類が行われます。
(3) CNN(Convolutional Neural Network, 畳み込みニューラルネットワーク)
wiki: 畳み込みニューラルネットワーク
現在、コンピュータビジョンの分野で広く使われているのが、CNN(畳み込みニューラルネットワーク)ベースのアーキテクチャです。商用アプリケーションの開発や、画像認識、物体検出、セマンティックセグメンテーションなどによく使われています。CNNは、画像の特徴を抽出するのに特に優れており、畳み込み層とプーリング層を組み合わせることで、画像内の重要な特徴を特定しやすくなります。 この方法により、画像を高速かつ正確に処理することができ、製品欠陥の自動検出、自動車運転支援システム、監視システム、医療画像解析など、多くの応用分野で活用されています。
CNNは、生の画像ピクセルから抽象的な特徴や概念を学習します。下記の画像を例をとして説明:
1. 最初の畳み込み層は、エッジや単純なテクスチャなどの特徴を学習
2. 後の畳み込み層は、より複雑なテクスチャやパターンなどの特徴を学習
3. その後の畳み込み層は、オブジェクトやオブジェクトの一部などの特徴を学習
4. 最後の全結合層は、前の層からの情報を統合し、出力を一次元の数値に変換します。この数値は、元の画像データがどのラベルに属するかを示す確率となります。
そのため、CNNは下位の畳み込み層(左側)では単純な特徴から始まり、上位の畳み込み層(右側)ではより抽象的な特徴まで幅広い範囲を学習します。

モデル: alexnet, vgg, googlenet, resnet, densenet など
CVモデル: SSD, R-CNN, Faster R-CNN, YOLO など
LeNetモデル: LeNet wikipedia
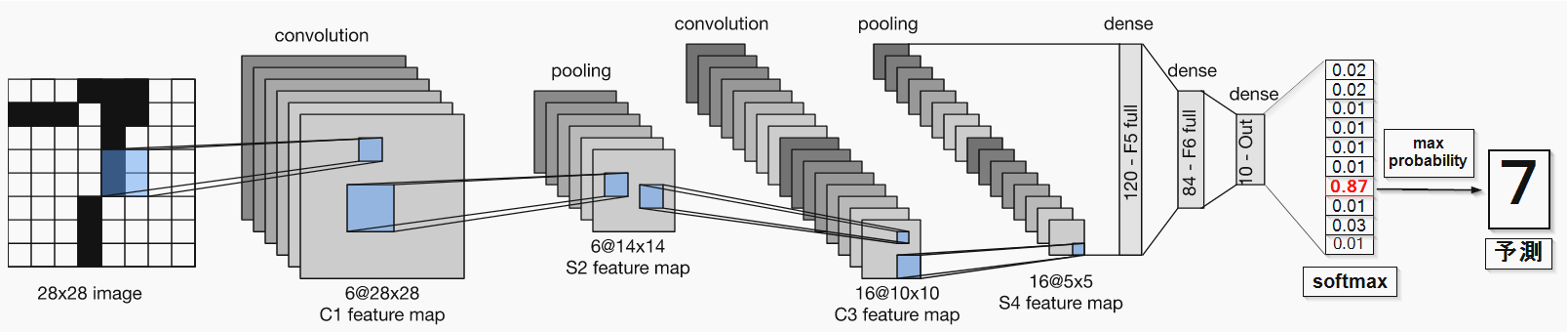 LeNet
LeNet
物体検出とインスタンスセグメンテーション: Mask R-CNN論文
 MASKRCNN
MASKRCNN
YOLO_v1(You Only Look Once)モデル: YOLO v1論文
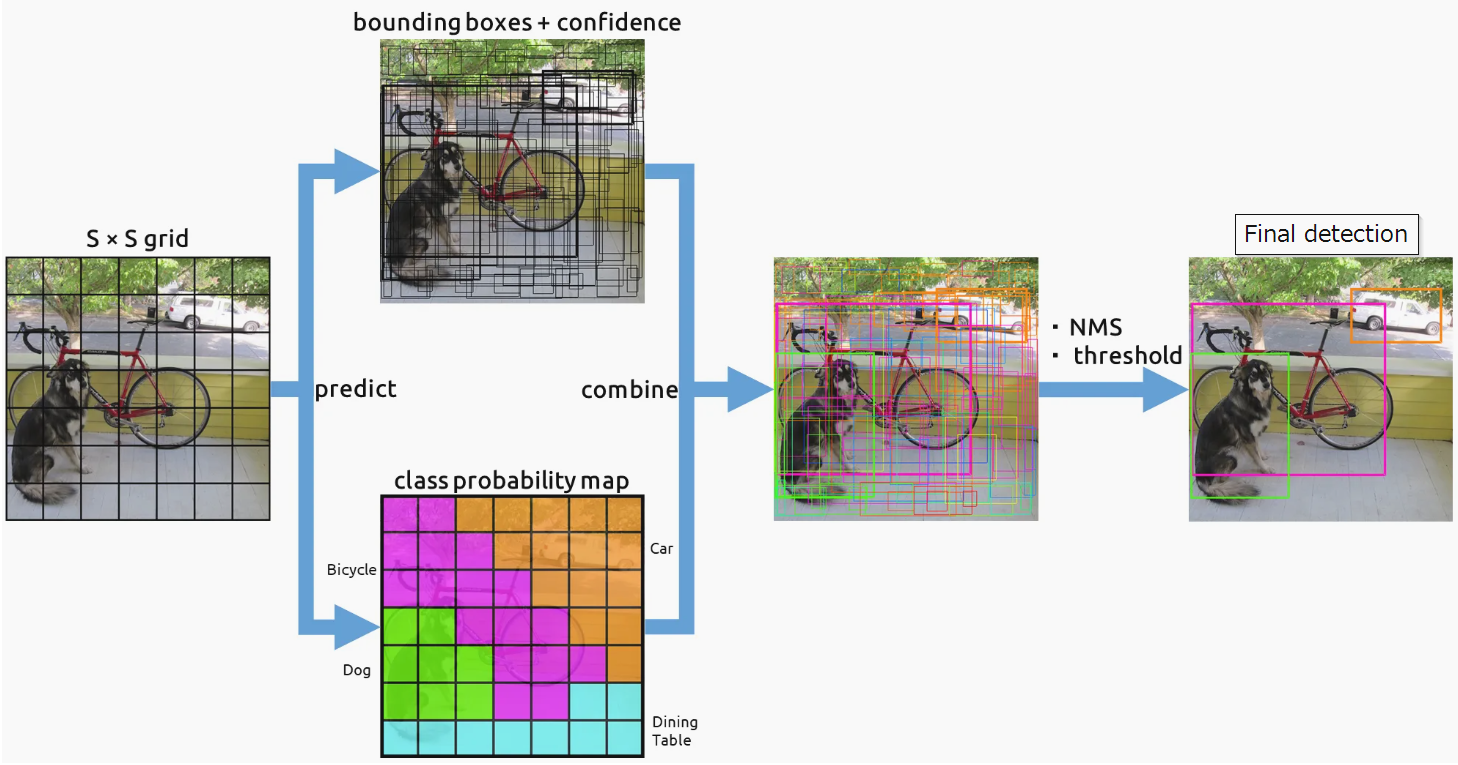 yolov1
yolov1
(4) RNN(Recurrent neural network, 回帰型ニューラルネットワーク)
wiki: 回帰型ニューラルネットワーク
リカレントニューラルネットワークは、過去の入力データの状態を保持するためのメモリ機能を持つニューラルネットワークです。CNNとRNNは、それぞれ異なる種類のデータ処理に適しています。CNNは画像や動画などの空間的または時間的なパターンを処理するのに適しています。一方、RNNは時系列データ、自然言語処理、音声認識などのように、入力が系列的なデータを処理するのに適しています。
モデル:GRU(ゲート付きリカレントユニット), LSTM(長短期記憶ネットワーク), encoder-decoder, seq2seq, beam-search など
YOLO_v1(You Only Look Once)モデル: YOLO v1論文
一般的なRNNモデル:
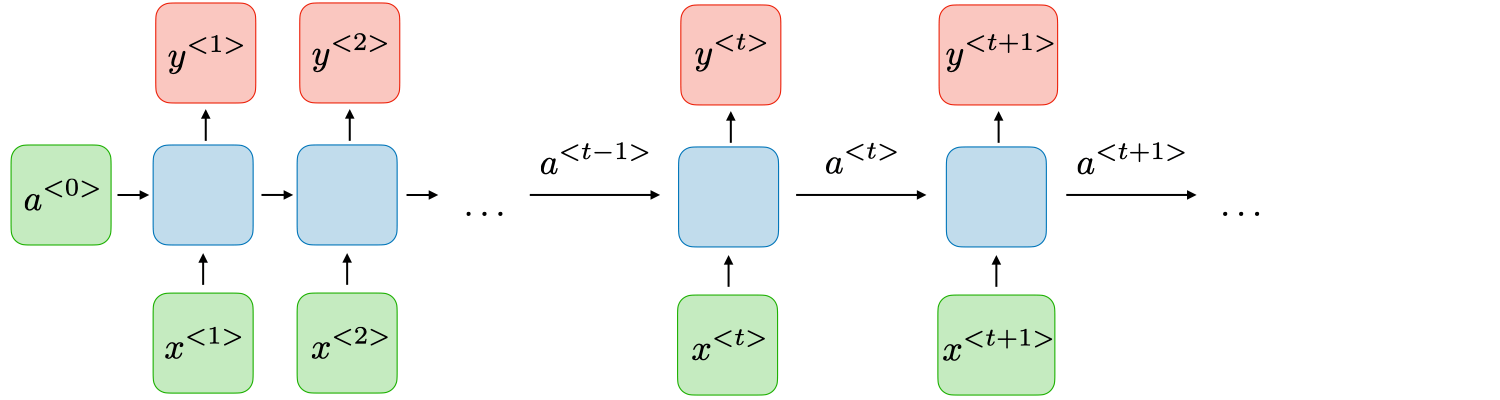
(5) 画像生成領域のモデル
(5)-1 GANs(Generative adversarial networks, 敵対的生成ネットワーク)
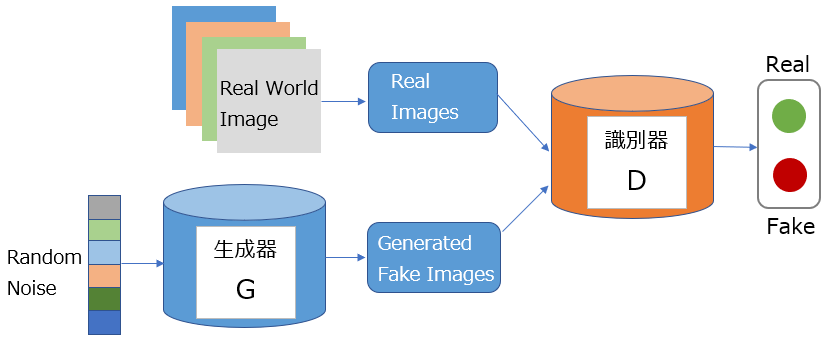
GANsは、2つのモデル(生成器: Generator と 識別器: Discriminator)を競わせ、リアルなデータと偽のデータを生成することで、新しいデータを生成する深層学習アルゴリズムです。生成器がデータを生成し、識別器がそれが本物かどうかを判断する過程が繰り返され、最終的に生成器は本物に近いデータを生成するようになります。
GANsは、生成能力が高いため、画像生成、画像修復、画像変換、音声生成、自然言語生成などの創造性のあるタスクに応用が可能です。また、データセットが不足している場合にも有用です。
モデル: CycleGAN, StyleGAN, DCGAN, Pix2Pix, SAGAN など
一般的なGANsモデル:
手書きの絵から本物そっくりの「猫」を作る: Image-to-Image Demo

(5)-2 Stable Diffusion
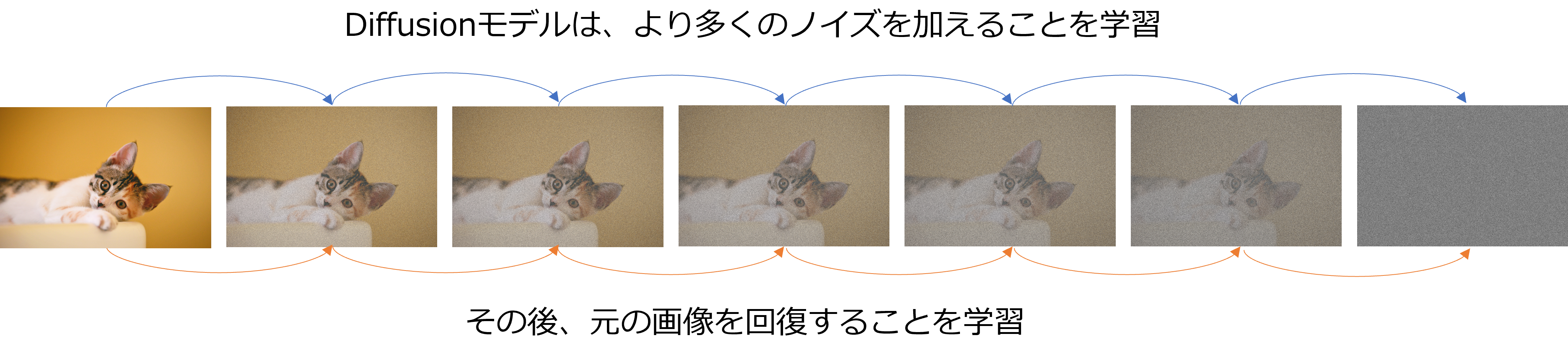
Stable Diffusionは、GANと同様に画像生成領域で用いられる手法の一つです。Stable Diffusionは、大域的最適化(Global Optimization)問題を解くことで、ランダムノイズから高品質で自然な画像を生成することができ、生成された画像の安定性や品質に優れています。
Stable Diffusionは、ノイズから開始して、少しずつ画像を生成するプロセスを反復的に繰り返すことで、高品質な画像を生成します。画像生成だけでなく、画像修復や画像変換など、様々なタスクに応用することができます。GANよりも高品質な画像を生成することができ、また、GANに比べてモード崩壊のリスクが低いとされています。しかし、計算コストが高い、処理時間がかかることが欠点とされています。
Stable Diffusionモデルの説明:
画像をランダムノイズ化してから、そのノイズを利用して画像を生成するAIモデル作ることを目指す。
Extended reading for Stable Diffusion: How to fine tune / train Stable Diffusion using Textual Inversion
Stable Diffusionモデルで文字を入力し、画像を生成するdemo(Text to Image): Stable Diffusion 2.1 Demo
(6) Transformer(トランスフォーマー)
Stanford University Course: CS25: Transformers United V2
トランスフォーマー(Transformer)は、最初は自然言語処理や音声認識などのタスクにおいて、高い精度を出すことで知られるニューラルネットワークのアーキテクチャの1つ、現在ではコンピュータビジョンの分野でも活用されています。従来のリカレントニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)よりも高速で並列化が容易であり、長期的な依存関係をモデル化することができます。
NLPタスクの多くで最先端の性能を発揮しています。例えば、機械翻訳、文章生成、感情分類、質問応答、文書分類、テキスト要約などがあります。
コンピュータビジョンでは、画像の生成、キャプション生成、物体検出、セマンティックセグメンテーションなどのタスクに使用されます。トランスフォーマーは、自己注意機構を使用して、画像内の異なる特徴の間の相互作用を考慮することができます。たとえば、画像内の異なるオブジェクトや領域の間の関係を理解することができます。CNNよりもより広範な画像の特徴を捉えることができ、より長期的な依存関係をキャプチャすることができます。
現在(2023.4)、世界で最も人気のある自然言語処理のモデルであるGPT(Generative Pre-trained Transformer)は、Transformerアーキテクチャのいくつかのブロックを使用して構築されています。一方、コンピュータビジョンにおいては、Transformerアーキテクチャを使用した最新の研究が進んでおり、一部のタスクで従来のCNNアーキテクチャに比べて優れた性能を発揮しています。例えば、物体検出やセマンティックセグメンテーションにおいて、Vision Transformer(ViT)と呼ばれるモデルが注目を集めています。
モデル: GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), ViT(Vision Transformer), DETR(End-to-End Object Detection with Transformers) など
GPTとは?
下記はTransformerによる自然言語処理(BERT モデル)の可視化:
Transformerは単語間の照応関係を考慮した学習が可能です。単語と全ての単語の間の関係をベクトルの内積で計算し、それを考慮することでより深く文脈を理解できます。
BERT論文: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
例文: today is a good day, let's go for a walk. goodとdayは最も強い関係があります。

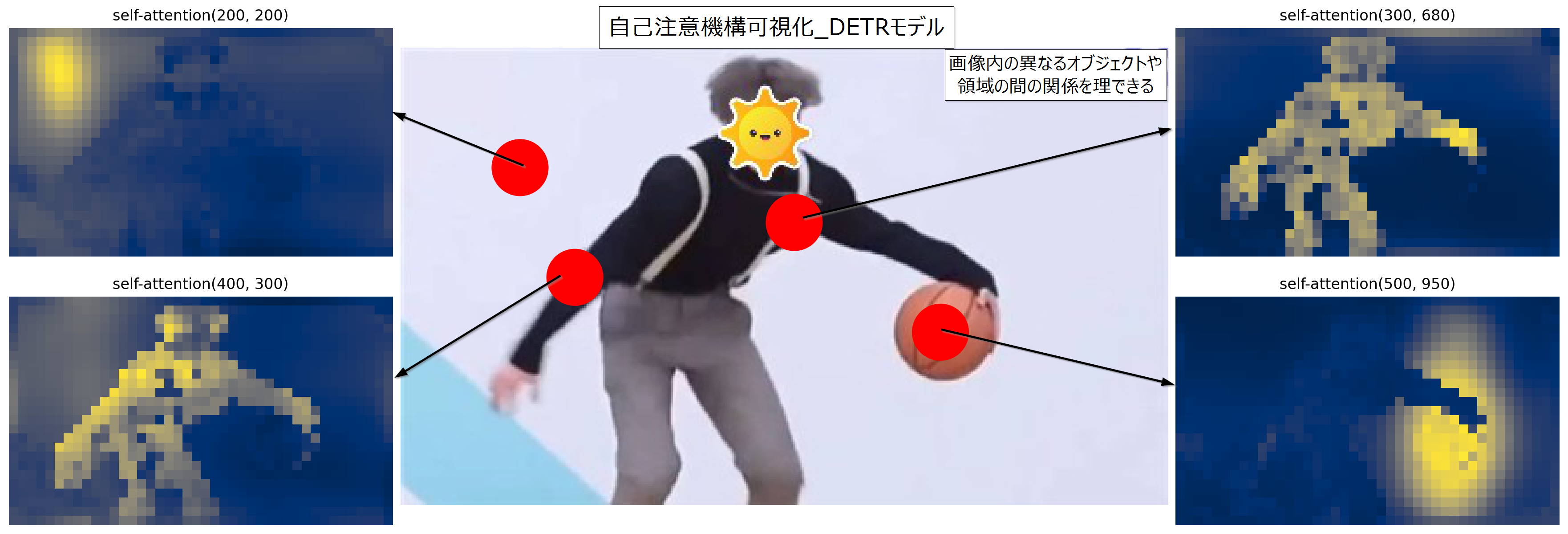
下記はTransformerによるコンピュータビジョン"DETR モデル"の可視化:
DETR(DEtection TRansformer)は、物体検出を行うために、まずCNNを使用して画像を特徴マップに変換します。そして、その特徴マップを入力として、Transformerを使用してオブジェクトの検出を行います。Tansformerを活用することでシンプルな構成でEnd to Endな物体検出を実現できます。
DETR論文: End-to-End Object Detection with Transformers
下図には、各ポイントが予測する際に注目している範囲が示されています。YES, I am ikun!
長文でしたが、最後まで読んで頂きましてありがとうございました。
この分野では、常に新しいテクノロジーやアルゴリズムが開発されているため、学習が止まることはありません。機械学習を学ぶことは、あなたのキャリアにとって非常に有益であり、現代社会においてもますます需要が高まっています。学び、実践し、ネットワークを構築し、質問してください。
この文章は2023年4月の情報を基に作成してあり、時間の経過とともに一部の内容は一致しなくなる可能性があります。
使用したモデルのPythonコードをお試したい場合はご連絡ください。